我們擅長(zhǎng)商業(yè)策略與用戶體驗(yàn)的完美結(jié)合。
歡迎瀏覽我們的案例。
蘋(píng)果新發(fā)布適用于蘋(píng)果芯片的機(jī)器學(xué)習(xí)框架 MLX,MLX 是一個(gè)類(lèi)似于 NumPy 的陣列框架,旨在為使用蘋(píng)果硬件的研究人員簡(jiǎn)化 ML 模型的訓(xùn)練和部署。
一直以來(lái),英偉達(dá) CUDA 稱(chēng)霸天下,使得它在 AI 領(lǐng)域的勢(shì)力不可動(dòng)搖。
對(duì)于許多人來(lái)說(shuō),都希望打破這個(gè)護(hù)城河,比如 PyTorch 支持更多 GPU,OpenAI 的 Triton 等等。

近日,蘋(píng)果針對(duì)使用蘋(píng)果芯片的機(jī)器學(xué)習(xí)研究人員,專(zhuān)門(mén)發(fā)布了一款機(jī)器學(xué)習(xí)框架 MLX。
蘋(píng)果機(jī)器學(xué)習(xí)團(tuán)隊(duì)的 Awni Hannun 在X-note 中將該軟件稱(chēng)為:「……專(zhuān)為蘋(píng)果芯片設(shè)計(jì)的高效機(jī)器學(xué)習(xí)框架」。
MLX 使用起來(lái)類(lèi)似 PyTorch、Jax 和 ArrayFire 等現(xiàn)有框架。
但是,MLX 針對(duì) Apple 芯片進(jìn)行了優(yōu)化。以前受困于艱難使用M芯片 GPU 跑模型的研究人員,現(xiàn)在終于可以擺脫這個(gè)苦惱了!
同時(shí),MLX 增加了對(duì)統(tǒng)一內(nèi)存模型的支持,這也意味著陣列位于共享內(nèi)存中,并且可以在任何支持的設(shè)備類(lèi)型上執(zhí)行操作,而無(wú)需執(zhí)行數(shù)據(jù)復(fù)制。那么,一旦蘋(píng)果的其他產(chǎn)品也能夠開(kāi)始跑模型……有沒(méi)有很期待!
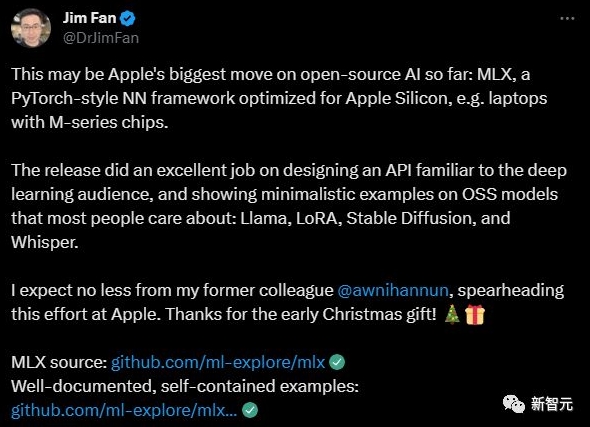
英偉達(dá)高級(jí)科學(xué)家 Jim Fan 表示,這可能是蘋(píng)果公司迄今為止在開(kāi)源人工智能方面的最大舉措:
MLX 特別之處
先讓我們來(lái)看看 MLX 的速度:
一位網(wǎng)友對(duì) MLX 的速度進(jìn)行了測(cè)試,他在推文中表示,使用 Apple MLX 框架進(jìn)行計(jì)算的速度,M2 Ultra(76 個(gè) GPU)可達(dá)到每秒 5 次迭代(It/sec),而 M3 Max(40 個(gè) GPU)可以達(dá)到每秒 2.8 次迭代。
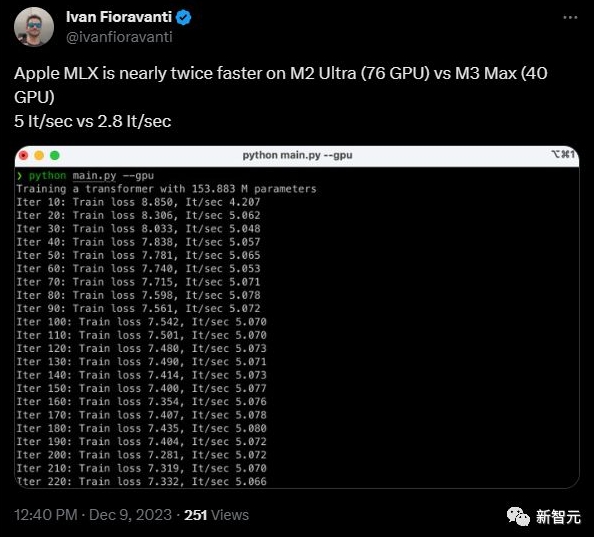
這個(gè)速度是與 Pytorch 幾乎持平的。
MLX 的另一大特點(diǎn),像 Jim Fan 指出的那樣,是它設(shè)計(jì)出色的 API。
對(duì)深度學(xué)習(xí)領(lǐng)域的開(kāi)發(fā)人員來(lái)說(shuō),上手幾乎零成本。
這是因?yàn)?MLX 的設(shè)計(jì)靈感來(lái)自于 PyTorch、Jax 和 ArrayFire 等現(xiàn)有框架。
研究團(tuán)隊(duì)解釋道:「Python API 與 NumPy 高度相似,只有少數(shù)例外。MLX 還擁有一個(gè)功能齊全的 C++ API,它與 Python API 高度一致。」
研究團(tuán)隊(duì)對(duì)該設(shè)計(jì)的目的作了補(bǔ)充:「該框架旨在兼顧對(duì)用戶操作友好,同時(shí)保持訓(xùn)練和部署模型的高效。我們的目標(biāo)是使研究人員能夠輕松擴(kuò)展和改進(jìn) MLX,以便快速探索新的想法。」
除了可以輕松上手的 API 之外,MLX 的一些其他關(guān)鍵特性還包括:
可組合的函數(shù)變換:MLX 含有用于自動(dòng)微分、自動(dòng)向量化和計(jì)算圖優(yōu)化的可組合函數(shù)變換,這對(duì)于優(yōu)化和加速機(jī)器學(xué)習(xí)模型的訓(xùn)練過(guò)程非常有用。
延遲計(jì)算:MLX 支持延遲計(jì)算,數(shù)組只在需要時(shí)才會(huì)被實(shí)例化。
動(dòng)態(tài)圖構(gòu)建:MLX 中的計(jì)算圖是動(dòng)態(tài)構(gòu)建的。改變函數(shù)參數(shù)的形狀不會(huì)觸發(fā)緩慢的編譯,調(diào)試也簡(jiǎn)單直觀。這使得模型的開(kāi)發(fā)和調(diào)試更加靈活和高效。
多設(shè)備支持:操作可以在任何支持的設(shè)備上運(yùn)行(目前支持 CPU 和 GPU)。
統(tǒng)一內(nèi)存:MLX 與其他框架的顯著區(qū)別在于統(tǒng)一的內(nèi)存模型。在 MLX 中,數(shù)組存在于共享內(nèi)存中,對(duì) MLX 數(shù)組的操作可以在任何支持的設(shè)備類(lèi)型上執(zhí)行,而無(wú)需移動(dòng)數(shù)據(jù)。
MLX Data
除了發(fā)布 MLX 以外,蘋(píng)果機(jī)器學(xué)習(xí)團(tuán)隊(duì)還一起發(fā)表了 MLX Data。這是一個(gè)與 MLX 框架無(wú)關(guān)的數(shù)據(jù)加載庫(kù),可以與 PyTorch、Jax 或 MLX 一同使用。
MLX Data 可以用于加載大規(guī)模數(shù)據(jù)集,也可以獨(dú)立用于數(shù)據(jù)預(yù)處理,以供機(jī)器學(xué)習(xí)訓(xùn)練使用。
該庫(kù)的目標(biāo)是允許用戶利用多線程來(lái)加速數(shù)據(jù)處理流水線,而無(wú)需涉及復(fù)雜的多進(jìn)程操作或使用符號(hào)語(yǔ)言編寫(xiě)代碼。這有利于幫助提高數(shù)據(jù)加載和預(yù)處理的效率。
MLX 示例展示
目前,用戶可以通過(guò) PyPI 輕松安裝 MLX,只需執(zhí)行以下命令:pip install mlx
用戶需要確保滿足以下安裝要求:
- 使用M系列芯片(蘋(píng)果芯片)
- 使用本地 Python 版本不低于 3.8
- MacOS 版本需不低于 13.3
研究團(tuán)隊(duì)同時(shí)提供了一系列有關(guān) MLX 功能的示例,包括 Transformer 語(yǔ)言模型訓(xùn)練、使用 LLaMA 進(jìn)行大規(guī)模文本生成、使用 LoRA 進(jìn)行微調(diào)、使用穩(wěn)定擴(kuò)散生成圖像,以及用 OpenAI 的 Whisper 進(jìn)行語(yǔ)音識(shí)別等。
這些例子也側(cè)面證明了該公司在語(yǔ)言處理、圖像生成和語(yǔ)音識(shí)別等方面的技術(shù)實(shí)力和工具的強(qiáng)大程度。
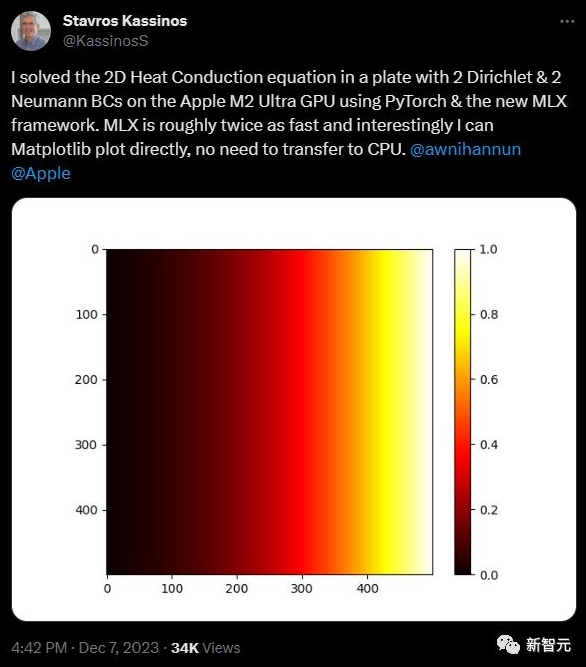
其他開(kāi)發(fā)人員也對(duì)于 MLX 進(jìn)行了其他有趣的嘗試,比如一位來(lái)自塞浦路斯大學(xué)的教授,在使用 PyTorch 和新的 MLX 框架的情況下,成功在 Apple M2 Ultra GPU 上解決了一個(gè)板上的二維熱傳導(dǎo)方程問(wèn)題,其中包含兩個(gè) Dirichlet 和兩個(gè) Neumann 邊界條件。
有趣的是,MLX 的計(jì)算速度大約是之前的兩倍,并且可以直接使用 Matplotlib 進(jìn)行繪圖,無(wú)需轉(zhuǎn)移到 CPU。
從 MLX 一瞥蘋(píng)果對(duì)于人工智能的展望
普惠機(jī)器學(xué)習(xí)
研究團(tuán)隊(duì)一再?gòu)?qiáng)調(diào),「MLX 是由機(jī)器學(xué)習(xí)研究人員為機(jī)器學(xué)習(xí)研究人員設(shè)計(jì)的。」 這表明蘋(píng)果意識(shí)到為機(jī)器學(xué)習(xí)開(kāi)發(fā)開(kāi)放、易于使用的開(kāi)發(fā)環(huán)境的需求,以促進(jìn)該領(lǐng)域的進(jìn)一步發(fā)展。
芯片技術(shù)
因?yàn)樘O(píng)果的處理器現(xiàn)在存在于其所有產(chǎn)品中,包括 Mac、iPhone 和 iPad。這種在這些芯片上使用 GPU、CPU 和(有可能在某個(gè)時(shí)刻)神經(jīng)引擎的方法可能會(huì)轉(zhuǎn)化為在設(shè)備上執(zhí)行 ML 模型。其性能可能超過(guò)其他處理器,至少在邊緣設(shè)備方面。
開(kāi)發(fā)工具的重要性
蘋(píng)果明確決定將重點(diǎn)放在為機(jī)器學(xué)習(xí)研究人員提供最佳工具上,包括強(qiáng)大的 M3 Mac,用于模型構(gòu)建。現(xiàn)在,他們進(jìn)一步希望將這種關(guān)注轉(zhuǎn)化為對(duì)普通用戶而言可行、以人為本的 AI 工具。
總體而言,蘋(píng)果希望通過(guò)提供強(qiáng)大的工具和在不同設(shè)備上的性能優(yōu)勢(shì),將機(jī)器學(xué)習(xí)和人工智能推向更廣泛的用戶。

蘋(píng)果版CUDA來(lái)了!專(zhuān)為自家芯片打造,M3 Max可跑每秒迭代2.8次 09:04:36
華為實(shí)現(xiàn)全國(guó)首個(gè)省域輕量化5G全網(wǎng)覆蓋:較4G可提升10倍 功耗低20% 09:24:57
全球首款“真無(wú)線”電視續(xù)作:新增 NFC 支付讀卡器和熱像儀 09:22:58
美團(tuán)無(wú)人機(jī)首條高校外賣(mài)航線在深圳開(kāi)航 09:20:17
高德地圖上線甘肅震區(qū)交通出行保障服務(wù):包含避難所和物資領(lǐng)取點(diǎn)查詢等 09:17:18
華為云與泰國(guó)氣象局聯(lián)合打造泰國(guó)盤(pán)古大模型:預(yù)測(cè)臺(tái)風(fēng)未來(lái)路徑從 5 小時(shí)縮短到 10 秒 09:15:45